但引人注目的是,上过大学但未获得学士学位的人(这一群体还包括社区大学毕业生)的工资溢价并没有上涨。高经济回报属于那些有四年制大学学位的人。这些回报突显了减少大学辍学率的重要性——在《纽约时报杂志》(Times Magazine)最近一篇文章中,保罗·塔夫(Paul Tough)描述了得克萨斯大学(University of Texas)为减少辍学率所做的努力。
function getHostname(url){ var a = document.createElement('a'); a.href = url; return a.hostname; }
function GetTopDomain(host){ if(host.indexOf("http") > -1) host = getHostname(host); var index = host.lastIndexOf('.'), last = 4; while (index> 0 && index>= last - 4){ last = index; index = host.lastIndexOf('.', last - 1); } var domain = host.substring(index + 1); return domain.length> 6 ? domain : host; }
为什么性能会影响公司的收益呢?根本原因还是在于性能影响了用户体验。加载的延迟、操作的卡顿等都会影响用户的使用体验。尤其是移动端,用户对页面响应延迟和连接中断的容忍度很低。想象一下你拿着手机打开一个网页想看到某个信息却加载半天的心情,你很可能选择直接离开换一个网页。谷歌也将页面加载速度作为 SEO 的一个权重,页面加载速度对用户体验和 SEO 的影响的调研有很多。
PhantomJS轻松地将监控带入了自动化的行列。Phantom JS 是一个服务器端的 JavaScript API 的 WebKit,基于它可以轻松实现 web 自动化测试。PhantomJS 需要一定编程工作,但也更灵活。官方文档中已经有一个完整的获取网页加载 har 文件的示例,具体说明可以查看此文档,国内也有不少关于此工具的介绍。另外新浪@貘吃馍香开发的类似工具berserkJS也挺不错,还贴心的提供了首屏统计的功能,具体文章可以查看此处。
对于用户来说他感觉到的为什么页面打不开、为什么按钮点击不了、为什么图片显示这么慢。而对于工程师来说,可能关注的是 DNS 查询、TCP 连接、服务响应等浏览器加载过程指标。我们根据用户的痛点,将浏览器加载过程抽取出四个关键指标,即白屏时间、首屏时间、用户可操作、总下载时间(定义可见上篇文章)。这些指标是如何统计的呢?
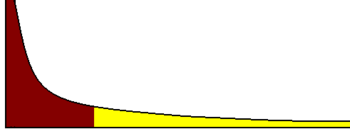
对于移动端来说,网络是页面加载速度最大的影响因素,需要根据不同的网络来采取相应的优化措施,例如对于 2G 用户采用简版等。但 web 上没有接口获取用户的网络类型。为了获取用户网络类型,可以通过测速的方式来判断不同 IP 段对应的网络。测速例如比较经典的有 facebook 的方案。经过测速后的分析,用户的加载速率有明显的分布区间,如下图所示:
各个分布区间正好对应不同的网络类型,经过与客户端的辅助测试,成功率可以在 95%以上。有了这个 IP 库对应的速率数据,就可以在分析用户数据时根据 IP 来判断用户网络类型。
小插曲 :之前从微博中看到有人评价说想做监控但是公司没有日志服务器。并不需要单独的日志服务器,只要能把统计的这个请求访问日志保存下来即可。如果网站自己的独立服务器都没有还有解决办法,在百度开发者中心新建一个应用,写一个简单的 Web 服务将接收到的统计数据解析存到百度云免费的数据库中,然后每天再用 Mysql 处理下当天的数据即可,对于普通站点的抽样性能数据应该没问题。请叫我雷锋。
[Editor’s note: to get short column names there’s an undocumented PRAGMA setting. You can exec “PRAGMA short_column_names = ON” to force that behavior.]
I noticed that if you use Joins in SQL queries, the field name is messed up with the dot! for example if you have this query: SELECT n.*, m.nickname FROM news AS n, members AS m WHERE n.memberID = m.id; now if you want to print_r the results returned using SQLITE_ASSOC type, the result array is like this : array ( [n.memberID] => 2 [n.title] => test title [m.nickname] => NeverMind [tablename.fieldname] => value ) and I think it looks horriable to use the variable ,for example, $news[‘m.nickname’] I just don’t like it!
so I’ve made a small function that will remove the table name (or its Alias) and will return the array after its index is cleaned
1 2 3 4 5 6 7 8 9 10 11 12 13 14
<?php functionCleanName($array) { foreach ($arrayas$key => $value) { //if you want to keep the old element with its key remove the following line unset($array[$key]);
//now we clean the key from the dot and tablename (alise) and set the new element $key = substr($key, strpos($key, '.')+1); $array[$key] = $value; } return$array; } ?>
Despite Google saying nothing is going on, we’ve been seeing signs of major changes and reports of major changes in the Google search results and rankings.
Again, over the weekend, I’ve been getting private emails with tons of public chatter in theWebmasterWorld and even BlackHatWorld forums about Google making a lot of changes over the weekend.
Some are suspecting a massive Penguin update is about to hit, while others think it might be a Panda refresh and others think it is just Google’s normal actions on link networks. It is almost impossible to tell without a confirmation from Google, for all we know, it can be all three or more.
Even the tracking tools are all over the place, it seems like it even broke MozCast,SERPS.com shows major activity on Saturday, so does SERP Metrics and Algoroo.
Here are some recent chatter comments from the forums:
Regardless of the weather anywhere overall my lowest-ever page views at 45.7% of 2014 average with the UK at 37.4% however fortunately not as bad as Friday at 26.5%, what a mess.
i did a small analysis.. i used two of my sites and ranked purely with GSA and 10 articles scraped and smashed one was used. it got hit.
for my one another site i used 5 unique articles, spun with wordai, smashed as 1 articles with GSA.. it got hit but only 4-9 position drops.. not like first one..
/** * Clear the cache for this entry and for all posts which are "related" to it. * @since 3.2 This is called when a post is deleted. */ functiondelete_post($post_ID) { // Clear the cache for this post. $this->clear((int) $post_ID);
// Find all "peers" which list this post as a related post and clear their caches if ($peers = $this->related(null, (int) $post_ID)) $this->clear($peers); }
/** * @since 3.4 Don't compute on revisions * @since 3.5 Compute on the parent instead */ if ($the_post = wp_is_post_revision($post_ID)) $post_ID = $the_post;
// Un-publish if ($old_status === 'publish' && $new_status !== 'publish') { // Find all "peers" which list this post as a related post and clear their caches if ($peers = $this->related(null, (int) $post_ID)) $this->clear($peers); }
// Publish if ($old_status !== 'publish' && $new_status === 'publish') { /* * Find everything which is related to this post, and clear them, * so that this post might show up as related to them. */ if ($related = $this->related($post_ID, null)) $this->clear($related); }
/** * @since 3.4 Simply clear the cache on save; don't recompute. */ $this->clear((int) $post_ID);
/** * Clear the cache for this entry and for all posts which are "related" to it. * @since 3.2 This is called when a post is deleted. */ functiondelete_post($post_ID) { // Clear the cache for this post. $this->clear((int) $post_ID);
$this->clearall();
// Find all "peers" which list this post as a related post and clear their caches if ($peers = $this->related(null, (int) $post_ID)) $this->clear($peers); } /** * @since 3.2.1 Handle various post_status transitions */ functiontransition_post_status($new_status, $old_status, $post) { $post_ID = $post->ID;
/** * @since 3.4 Don't compute on revisions * @since 3.5 Compute on the parent instead */ if ($the_post = wp_is_post_revision($post_ID)) $post_ID = $the_post;
// Un-publish if ($old_status === 'publish' && $new_status !== 'publish') { // Find all "peers" which list this post as a related post and clear their caches if ($peers = $this->related(null, (int) $post_ID)) $this->clear($peers); }
// Publish if ($old_status !== 'publish' && $new_status === 'publish') { /* * Find everything which is related to this post, and clear them, * so that this post might show up as related to them. */ if ($related = $this->related($post_ID, null)) $this->clear($related); }
/** * @since 3.4 Simply clear the cache on save; don't recompute. */ $this->clear((int) $post_ID);