[program: ] ( is name of program) command=/bin/ //Execute command process_name=%(program_name)s //if your numprocs is more than 1 it should be %(program_name)s_%(process_num)02d numprocs=1//Number of your concurrent process Perfect for gearman directory=/tmp //cd this directory before running priority=999//priority or program maximum is 999 autostart=true autorestart=true startretries=3//number of retrying times if process is die stopwaitsecs=10//waiting xx second before before stop user=chrism //exec by user should be “root” //Log control stdout_logfile=/a/path stdout_logfile_maxbytes=1MB
sudo vi /etc/rc.d/init.d/supervisord #!/bin/sh # # /etc/rc.d/init.d/supervisord # # Supervisor is a client/server system that # allows its users to monitor and control a # number of processes on UNIX-like operating # systems. # # chkconfig: - 64 36 # description: Supervisor Server # processname: supervisord
for i inrange( 10 ): time.sleep( random.randrange( 4 ) ) print"%s attempting to read %s..." % ( self.getName(), current + 1 ) current = self.sharedObject.get() print"%s read %s" % ( self.getName(), current ) sum += current
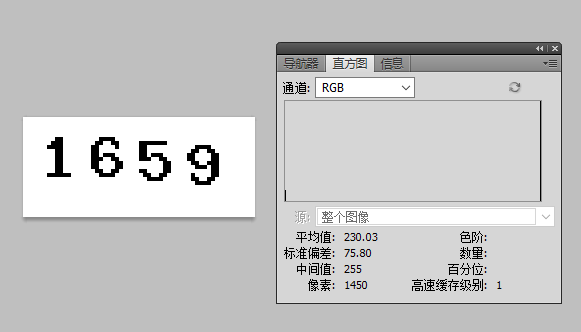
im = Image.open("captcha.gif") im = im.convert("P") im2 = Image.new("P",im.size,255)
im = im.convert("P")
temp = {}
for x inrange(im.size[1]): for y inrange(im.size[0]): pix = im.getpixel((y,x)) temp[pix] = pix if pix == 220or pix == 227: # these are the numbers to get im2.putpixel((y,x),0)
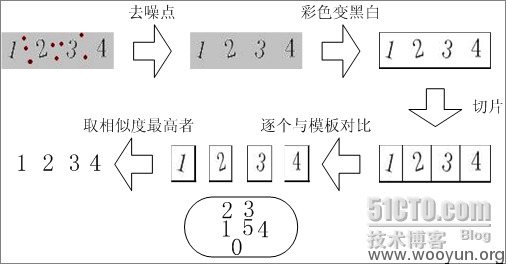
for each binary image: for each pixel in the binary image: if the pixel is on: ifany pixel we have seen before isnext to it: add to the same set else: add to a new set
#!/usr/bin/env python # -*- coding: UTF-8 -*- #图像二值处理 import os from PIL import Image j=1 dir="./pic/" path = "./font/" for f in os.listdir(dir): if f.endswith(".gif"): img = Image.open(dir+f) # 读入图片 img = img.convert("RGBA") pixdata = img.load() #二值化 for y in xrange(img.size[1]): for x in xrange(img.size[0]): if pixdata[x, y][0] < 90: pixdata[x, y] = (0, 0, 0, 255) for y in xrange(img.size[1]): for x in xrange(img.size[0]): if pixdata[x, y][1] < 136: pixdata[x, y] = (0, 0, 0, 255) for y in xrange(img.size[1]): for x in xrange(img.size[0]): if pixdata[x, y][2] > 0: pixdata[x, y] = (255, 255, 255, 255) img.save(path+f, "GIF")
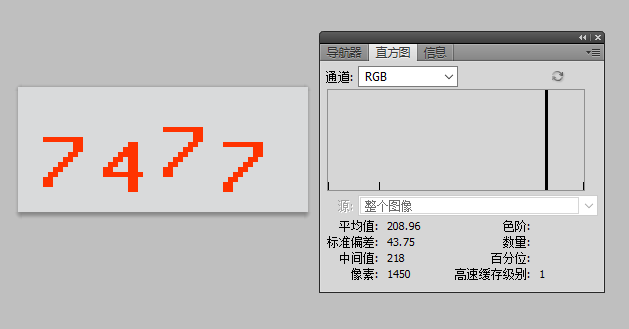
im = Image.open("captcha.gif") im = im.convert("P") im2 = Image.new("P",im.size,255)
im = im.convert("P")
temp = {}
for x inrange(im.size[1]): for y inrange(im.size[0]): pix = im.getpixel((y,x)) temp[pix] = pix if pix == 220or pix == 227: # these are the numbers to get im2.putpixel((y,x),0)
# new code starts here
inletter = False foundletter=False start = 0 end = 0
letters = []
for y inrange(im2.size[0]): # slice across for x inrange(im2.size[1]): # slice down pix = im2.getpixel((y,x)) if pix != 255: inletter = True if foundletter == Falseand inletter == True: foundletter = True start = y
if foundletter == Trueand inletter == False: foundletter = False end = y letters.append((start,end))
#!/usr/bin/env python # -*- coding: UTF-8 -*- #图像分割 import os ,Image j = 1 dir="./font/" for f in os.listdir(dir): if f.endswith(".gif"): img = Image.open(dir+f) for i inrange(4): x = 16 + i*15#这里的数字参数需要自己 y = 2#根据验证码图片的像素进行 img.crop((x, y, x+7, y+10)).save("fonts/%d.gif" % j) #适当的修改 print"j=",j j += 1
defcontent_to_file(content, num): f = open('%s%d.png'%(file_path, num), 'wb') f.write(content) f.close()
defmain(): times = 100 print('%d files needed.'%times) for i inrange(times): num_of_file = i c = get_content() content_to_file(c, i) print('%d files done.'%i) time.sleep(2)
# load font modules (char, image) fontMods = [] for i inrange(10): fontMods.append((str(i), Image.open("./good/%02d.bmp" % i))) for i inrange(26): c = chr(ord('A') + i) fontMods.append((c, Image.open("./good/%s.bmp" % c)))
defrecognize(f): im = Image.open(f) im2 = im.convert('1') # check 5 fonts result = "./result/" for i inrange(5): x = 10 + i*18 y = 6 target = im.crop((x, y, x+8, y+10)) points = [] for mod in fontMods: diffs = 0 for yi inrange(10): for xi inrange(8): if mod[1].getpixel((xi, yi)) != target.getpixel((xi, yi)): diffs += 1 points.append((diffs, mod[0])) points.sort() result += points[0][1] result += ".png" print"save to", result im.save(result);
for imgfile in os.listdir("."): if imgfile.endswith(".png"): recognize(imgfile)
defbinary(f): print(f) img = Image.open(f) #img = img.convert('1') img = img.convert("RGB") # 参考文章中无该行,无该行,我这里会报错 pixdata = img.load() for y inrange(img.size[1]): for x inrange(img.size[0]): if pixdata[x, y][0] < 90: pixdata[x, y] = (0, 0, 0, 255) for y inrange(img.size[1]): for x inrange(img.size[0]): if pixdata[x, y][1] < 136: pixdata[x, y] = (0, 0, 0, 255) for y inrange(img.size[1]): for x inrange(img.size[0]): if pixdata[x, y][2] > 0: pixdata[x, y] = (255, 255, 255, 255) return img nume = 0
#图像的分割,就是验证码按字符分割出来
defdivision(img): global nume font = [] for i inrange(4): x = 2 + i*10# 该函数中的像素值都需要自己进行微调 y = 0 temp = img.crop((x, y, x + 6, y + 10)) temp.save("./temp/%d.bmp" % nume) nume = nume + 1 font.append(temp) return font
#分隔出来的字符与预先定义的字体库中的结果逐个像素进行对比找出差别最小的项
defrecognize(img):
fontMods = [] for i inrange(10): fontMods.append((str(i), Image.open("./num/%d.bmp" % i))) result = "" font = division(img) for i in font: target = i points = [] print("正在比对数字:{0}".format(i)) for mod in fontMods: print("test fontmods {0}".format(mod)) diffs = 0 for yi inrange(10): for xi inrange(6): # print(xi, yi, "mod[1].getpixel((xi, yi)):"+str(mod[1].getpixel((xi, yi)))) # print(xi, yi, "target.getpixel((xi, yi)):"+str(target.getpixel((xi, yi))))
print("diffs:" + str(diffs)) points.append((diffs, mod[0])) points.sort() result += points[0][1] return result if __name__ == '__main__': codedir = "./pic/" for imgfile in os.listdir(codedir): if imgfile.endswith(".bmp"): dir = "./result/" img = binary(codedir+imgfile) num = recognize(img) dir += (num + ".gif") print("save to", dir) img.save(dir)
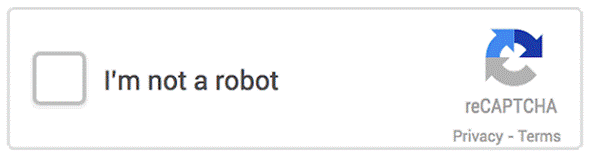
验证码(CAPTCHA)或者叫做全自动区分计算机和人类的图灵测试(Completely Automated Public Turing test to tell Computers and Humans Apart),使我们上网的人每天都可以见到的,而它的作用除了防止垃圾注册或者评论以外还有别的吗?来自Google的reCAPTCHA(上图)告诉我们,你其实还可以为人类做贡献。