简单图形验证码识别
纯文本验证码、图形验证码、声音验证码、JS验证码,以下主要讲简单的图形验证码的识别。
在破解验证码中需要用到的知识一般是 像素,线,面等基本2维图形元素的处理和色差分析。常见工具为:
- 支持向量机(SVM)
支持向量机SVM是一个机器学习领域里常用到的分类器,可以对图形进行边界区分,不过需要的背景知识太高深。 - OpenCV
OpenCV是一个很常用的计算机图像处理和机器视觉库,一般用于人脸识别,跟踪移动物体等等。 - 图像处理软件(Photoshop,Gimp…)
- Python Image Library
Python Image Library是pyhon里面带的一个图形处理库,功能比较强大,是我们的首选。
识别验证码需要充分利用图片中的信息,才能把验证码的文字和背景部分分离,一张典型的jpeg图片,每个像素都可以放在一个5维的空间里,这5个维度分别是,X,Y,R,G,B,也就是像素的坐标和颜色,在计算机图形学中,有很多种色彩空间,最常用的比如RGB,印刷用的CYMK,还有比较少见的HSL或者HSV,每种色彩空间的维度都不一样,但是可以通过公式互相转换。
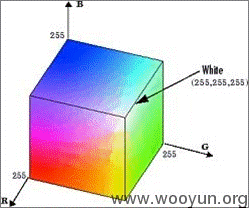
RGB色彩空间构成的立方体,每个维度代表一种颜色
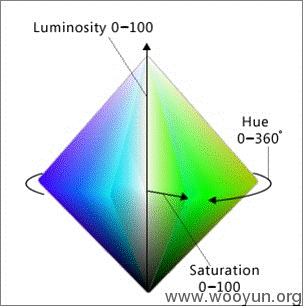
HSL(色相饱和度)色彩空间构成的锥体,可以参考:
https://zh.wikipedia.org/wiki/HSL%E5%92%8CHSV%E8%89%B2%E5%BD%A9%E7%A9%BA%E9%97%B4
HSL和HSV都是一种将RGB色彩模型中的点在圆柱坐标系中的表示法。这两种表示法试图做到比RGB基于笛卡尔坐标系的几何结构更加直观。
HSL即色相、饱和度、亮度(英语:Hue, Saturation, Lightness),又称HSL。HSV即色相、饱和度、明度(英语:Hue, Saturation, Value),又称HSB,其中B即英语:Brightness。
- 色相(H)是色彩的基本属性,就是平常所说的颜色名称,如红色、黄色等。
- 饱和度(S)是指色彩的纯度,越高色彩越纯,低则逐渐变灰,取0-100%的数值。
- 明度(V),亮度(L),取0-100%。
了解到色彩空间的原理,就可以用在该空间适用的公式来进行像素的色差判断,比如RGB空间里判断两个点的色差可以用3维空间中两坐标求距离的公式:
distance=sqrt[(r1-r2)^2+(g1-g2)^2+(b1-b2)^2]
更加直观的图片,大家感受一下:
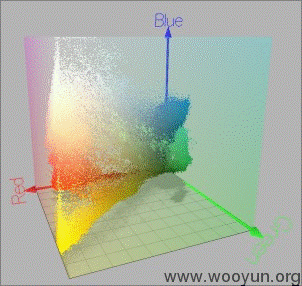
随便把一张图片的每个像素都映射到RGB色彩空间里就能获得一个这样的立方体。
通过对像素颜色进行统计和区分,可以获得图片的颜色分布,在验证码中,一般来说使用近似颜色最多的像素都是背景,最少的一般为干扰点,干扰线和需要识别文字本身。
验证码识别的原理和过程
第一步: 二值化
所谓二值化就是把不需要的信息通通去除,比如背景,干扰线,干扰像素等等,只剩下需要识别的文字,让图片变成2进制点阵。

第二步: 文字分割
为了能识别出字符,需要对要识别的文字图图片进行分割,把每个字符作为单独的一个图片看待。

第三步:标准化
对于部分特殊的验证码,需要对分割后的图片进行标准化处理,也就是说尽量把每个相同的字符都变成一样的格式,减少随机的程度
最简单的比如旋转还原,复杂点的比如扭曲还原等等
第四步:识别
这一步可以用很多种方法,最简单的就是模板对比,对每个出现过的字符进行处理后把点阵变成字符串,标明是什么字符后,通过字符串对比来判断相似度。
在文章的后半部分会详细解释每步的各种算法
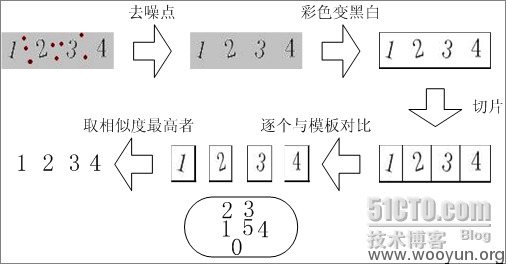
二值化算法
直方图
这是一张图像的亮度(Luminosity)+RGB三通道的直方图。
直方图的观看规则就是“左黑右白”,左边代表暗部,右边代表亮部,而中间则代表中间调。亮度从0–255,0表示黑,255表示白。如果某个地方的峰越高,表示在这个亮度下的像素越多。这个相片的直方图说明图片整体是偏亮的。
纵向上的高度代表像素密集程度,越高,代表的就是分布在这个亮度上的像素很多。
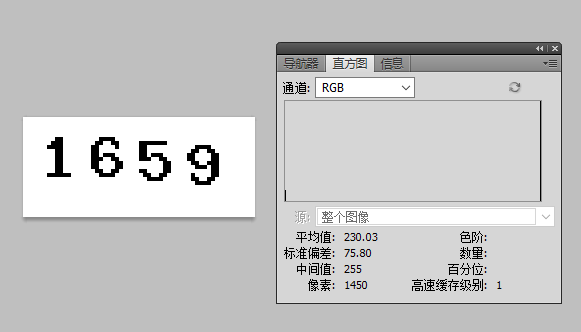
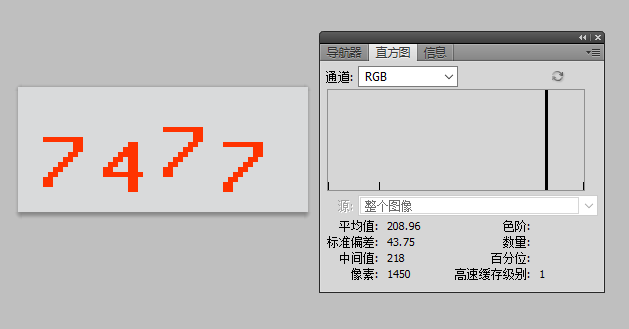
先建立一个图像中的颜色直方图,通过把所有像素按颜色分组实现

1 | from PIL import Image |
输出
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0
, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0,
1, 0, 0, 2, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 2, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1,
0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 2, 1, 0, 0, 0, 2, 0, 0, 0, 0, 1, 0, 1, 1, 0, 0
, 1, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 2, 0, 0, 0, 1, 2, 0, 1, 0, 0, 1,
0, 2, 0, 0, 1, 0, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 0, 3, 1, 3, 3, 0,
0, 0, 0, 0, 0, 1, 0, 3, 2, 132, 1, 1, 0, 0, 0, 1, 2, 0, 0, 0, 0, 0, 0, 0, 15, 0
, 1, 0, 1, 0, 0, 8, 1, 0, 0, 0, 0, 1, 6, 0, 2, 0, 0, 0, 0, 18, 1, 1, 1, 1, 1, 2,
365, 115, 0, 1, 0, 0, 0, 135, 186, 0, 0, 1, 0, 0, 0, 116, 3, 0, 0, 0, 0, 0, 21,
1, 1, 0, 0, 0, 2, 10, 2, 0, 0, 0, 0, 2, 10, 0, 0, 0, 0, 1, 0, 625]
1 | from PIL import Image |
1 | 255 625 |
第一列是颜色的ID,第二列是相对应的颜色的数量,图片中可见白色最多,其次是灰色和红色
上面显示一共有10个颜色在这个图片中,红色应该是第三个常见颜色220,但是上面中227与220非常接近,把它也包含进去。这张图中220 与227应该是红色部分,也就是我们想保留的验证码部分,其它颜色可以去掉, 创建一个新的二色图像,只有白黑。
1 | from PIL import Image |
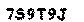
上面这个黑白图片便是我们成功提取到的只有字母数字的图像,正是我们需要的,如果图片中的验证码是多个颜色,判断上面会相应复杂一些。
1 | for each binary image: |
二值化处理的另外一种算法
1 | #!/usr/bin/env python |
切割字符

主要代码
1 | from PIL import Image |
1 | [(6, 14), (15, 25), (27, 35), (37, 46), (48, 56), (57, 67)] |
这些是每个字符在图片水平方向的开始位置与结束位置,如果验证码的每个字符的位置是固定的就不需要上面这种方法,可以直接指定。
固定位置的字符切割算法
1 | #!/usr/bin/env python |
接下来需要比对每个字符与模板的相似度,我们使用一种最简单的方法。但前提是我们需要生成比对的模板匹配库,可以通过以下代码生成。
1 | # New code is here. We just extract each image and save it to disk with |
上面的代码会在同一目录下生成一组图像组合,每个图像都是切割出来的单个字符,每个图像都有一个唯一的哈希值命名,你可以选择你需要的字符集。

从这些字模之中,每个数字或字母,我们只需要一个看上去比较标准的就够了。

上面是我生成的模板。
批量下载验证码
为了实现匹配库,需要批量下载一些验证码。
1 | import sys, base64 |
一个简单的识别程序
1 | import os, Image |
一个完整的例子
1 | #!/usr/bin/env python |
说说12306的验证码
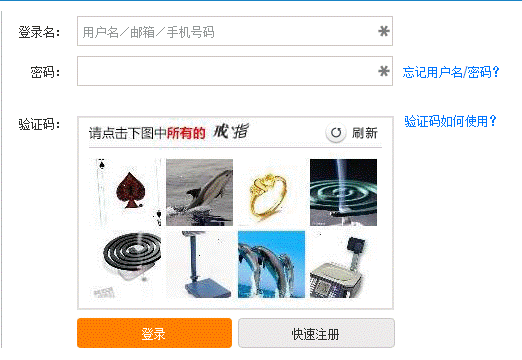
● 用户体验不高,故意对用户复杂但对机器不一定复杂
● 容易被枚举,题库太弱,毕竟是人采集的图片,总有上限,不如字符组合可能性多
● 破解门槛不一定高于字符型Captcha
● 任何的验证码都抵不过分布式人工打码方案
先看下网上有人试图破解的

reCAPTCHA
验证码(CAPTCHA)或者叫做全自动区分计算机和人类的图灵测试(Completely Automated Public Turing test to tell Computers and Humans Apart),使我们上网的人每天都可以见到的,而它的作用除了防止垃圾注册或者评论以外还有别的吗?来自Google的reCAPTCHA(上图)告诉我们,你其实还可以为人类做贡献。
如果我们想电子化一些从前的文档,比如 19 世纪的纽约时报,我们要不得依靠人力,手动地一个一个字地输入电脑,要不然就直接扫描,然后用软件识别。但是软件识别的准确率不能保证,尤其是扫描或者文档本身质量很差的时候,比如:

reCAPTCHA 做的,简单来说就是把上图的单词切割抽取出来,然后与一组自动生成的字符混合,生成验证码,发送到各各网站上,像这样:

reCAPTCHA 默认如果电脑产生的字符你输入正确,那么从文档中抽取的字符你的输入也将是正确的,然后通过交叉验证,重复验证,各种算法保证准确率。于是坐在电脑前上网的我们,每次输入验证码的时候,就可能顺便为某个图书馆的文档录入做出了贡献。详细点的介绍可看:关于 reCAPTCHA 验证码 。
一个经常被提到的实例就是,借助广大网民之手,纽约时报从 1851 年到现在的所有报纸,总共超过 1 千 3 百万篇文章都已经成功录入计算机。如果依靠手工输入,人力,资金,时间都将是巨大的,然而借助 reCAPTCHA, 以及每天上网的我们,这项工作短时间内已经完成了。
09 年 reCAPTCHA 被谷歌收购了,大家可能也都注意到了,谷歌更进一步利用验证码来帮助它们识别门牌号,路牌等等,用来修正谷歌地图的精度。这样谷歌地图的准确度,以及用户的体验都得到了提升。

谷歌让验证码更简单

尽管验证码在阻止垃圾邮件发送者和数字化传统文本方面非常有效,但是也有局限性。验证码没有音频选项,无法让视障人群进入被保护网站。没有视力问题的用户也抱怨,因为有些文字太难认。四年前,斯坦福大学的一群研究者收集了 30 多万个谷歌、雅虎和微软使用过的验证码,进行了一项研究。研究者在
caption-bypass.com 和亚马逊土耳其机器人系统让用户辨别验证码。研究人员向三个不同的人展示验证码,但是他们都同意正确答案的几率只有 71%。
另一个问题是利用多种多样的算法验证码也能遭到破解。今年早些时候,谷歌街景和 reCAPTCHA 团队的成员发表了一篇论文,论文内容是他们用于破解自家的验证码的一种算法。谷歌在一篇博文中表示:「我们最近的研究说明,现在的人工智能技术能以 99.8% 的正确率识别最扭曲最有难度的验证码文字。因此扭曲文字不再是一种可靠的测试方法了。」验证码还有很大的改进空间。因此诞生了 No CAPTCHA reCAPTCHA。
No CAPTCHA reCAPTCHA
谷歌最近发布了一种新的应用程序界面(API),叫做 No CAPTCHA reCAPTCHA,它大大简化了判断用户是人类与否的步骤。通过 No CAPTCHA reCAPTCHA,用户只需要简单的点击「我不是机器人」这句话边上的复选框就可以确定他们是人类了。No CAPTCHA reCAPTCHA 已经整合到了 WordPress,Snapchat 和 Humble Bundle 等服务中了。No CAPTCHA ReCAPTCHA 可能看起来更容易被垃圾邮件发送者破解,但是谷歌开发了一套复杂的高级风险分析后端在决定用户是人类的过程中分析用户参与识别的情况。
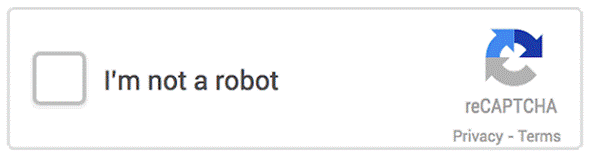
大多数用户可能很容易就点击复选框然后继续了,但是可疑的人类或者机器人可能会强制回答电脑屏幕上的验证码或者移动设备上的动物配对测试:

参考文章
http://drops.wooyun.org/tips/141
http://blog.csdn.net/shuifa2008/article/details/45692823
http://xiaoxia.org/2011/05/31/boring-entry-the-fabled-verification-code-recognition-technology-learning-notes/
http://www.codeproject.com/Articles/106583/Handwriting-Recognition-Revisited-Kernel-Support-V